. Exploratory Data Analysis in R
From this section onwards,
we’ll dive deep into various stages of predictive modeling. Hence, make
sure you understand every aspect of this section. In case you find anything
difficult to understand, ask me in the comments section below.
Data Exploration is a
crucial stage of predictive model. You can’t build great and practical models
unless you learn to explore the data from begin to end. This stage forms a
concrete foundation for data manipulation (the very next stage). Let’s
understand it in R.
In this tutorial, I’ve
taken the data set from Big Data Mart Sales Prediction. Before we start, you
must get familiar with these terms:
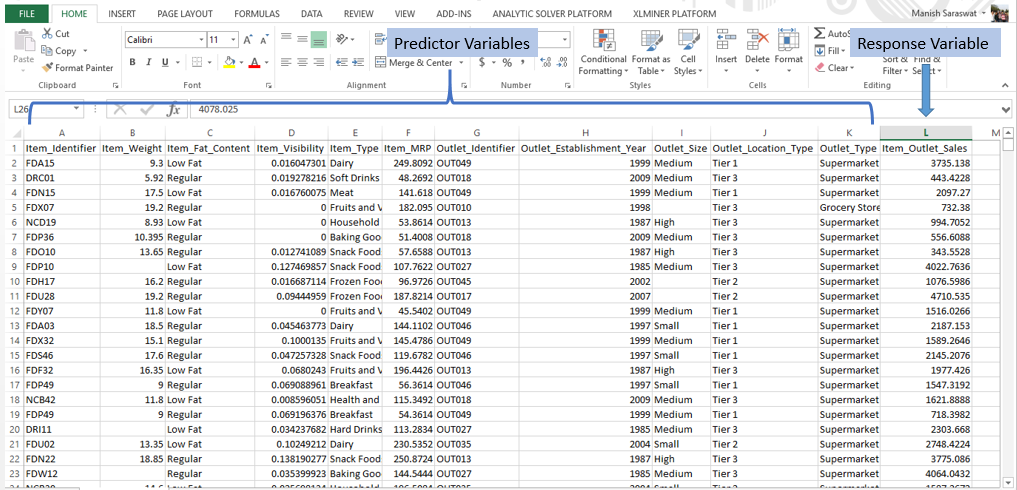
Response
Variable (a.k.a Dependent Variable): In a data set, the response variable (y) is
one on which we make predictions. In this case, we’ll predict
‘Item_Outlet_Sales’. (Refer to image shown below)
Predictor
Variable (a.k.a Independent Variable):
In a data set, predictor variables (Xi) are those using which the
prediction is made on response variable. (Image below).
{kind=link}
Train Data: The predictive model is always built on train
data set. An intuitive way to identify the train data is, that it always has
the ‘response variable’ included.
DOWNLOAD TRAIN DATA
DOWNLOAD TRAIN DATA
Test Data: Once the model is built, it’s accuracy is
‘tested’ on test data. This data always contains less number of observations
than train data set. Also, it does not include ‘response variable’.
DOWNLOAD TEST DATA
DOWNLOAD TEST DATA
Right now, you should
download the data set. Take a good look at train and test data. Cross check the
information shared above and then proceed.
Let’s now begin with importing and exploring data.
#working directory
path <- ".../Data/BigMartSales"#set working directory
setwd(path)
As a beginner, I’ll advise you
to keep the train and test files in your working directly to avoid unnecessary
directory troubles. Once the directory is set, we can easily import the
.csv files using commands below.
#Load Datasets
train <-
read.csv("Train_UWu5bXk.csv")test <- read.csv("Test_u94Q5KV.csv")
In fact, even prior to
loading data in R, it’s a good practice to look at the data in Excel. This
helps in strategizing the complete prediction modeling process. To check
if the data set has been loaded successfully, look at R environment. The data
can be seen there. Let’s explore the data quickly.
#check dimesions ( number of row & columns)
in data set
> dim(train)[1] 8523 12
> dim(test)
[1] 5681 11
We have 8523 rows and 12
columns in train data set and 5681 rows and 11 columns in data set. This makes
sense. Test data should always have one column less (mentioned above right?).
Let’s get deeper in train data set now.
#check the variables and their types in train
> str(train)'data.frame': 8523 obs. of 12 variables:
$ Item_Identifier : Factor w/ 1559 levels "DRA12","DRA24",..: 157 9 663 1122 1298 759 697 739 441 991 ...
$ Item_Weight : num 9.3 5.92 17.5 19.2 8.93 ...
$ Item_Fat_Content : Factor w/ 5 levels "LF","low fat",..: 3 5 3 5 3 5 5 3 5 5 ...
$ Item_Visibility : num 0.016 0.0193 0.0168 0 0 ...
$ Item_Type : Factor w/ 16 levels "Baking Goods",..: 5 15 11 7 10 1 14 14 6 6 ...
$ Item_MRP : num 249.8 48.3 141.6 182.1 53.9 ...
$ Outlet_Identifier : Factor w/ 10 levels "OUT010","OUT013",..: 10 4 10 1 2 4 2 6 8 3 ...
$ Outlet_Establishment_Year: int 1999 2009 1999 1998 1987 2009 1987 1985 2002 2007 ...
$ Outlet_Size : Factor w/ 4 levels "","High","Medium",..: 3 3 3 1 2 3 2 3 1 1 ...
$ Outlet_Location_Type : Factor w/ 3 levels "Tier 1","Tier 2",..: 1 3 1 3 3 3 3 3 2 2 ...
$ Outlet_Type : Factor w/ 4 levels "Grocery Store",..: 2 3 2 1 2 3 2 4 2 2 ...
$ Item_Outlet_Sales : num 3735 443 2097 732 995 ...
Let’s do some quick data exploration.
To begin with, I’ll first check if this data has
missing values. This can be done by using:
> table(is.na(train))
FALSE TRUE
100813 1463
In train data set, we have
1463 missing values. Let’s check the variables in which these values are
missing. It’s important to find and locate these missing values. Many data
scientists have repeatedly advised beginners to pay close attention to missing
value in data exploration stages.
> colSums(is.na(train))
Item_Identifier Item_Weight 0 1463
Item_Fat_Content Item_Visibility
0 0
Item_Type Item_MRP
0 0
Outlet_Identifier Outlet_Establishment_Year
0 0
Outlet_Size Outlet_Location_Type
0 0
Outlet_Type Item_Outlet_Sales
0 0
Hence, we see that column Item_Weight has 1463
missing values. Let’s get more inferences from this data.
> summary(train)
Here are some quick inferences drawn from
variables in train data set:
- Item_Fat_Content has
mis-matched factor levels.
- Minimum value of
item_visibility is 0. Practically, this is not possible. If an item
occupies shelf space in a grocery store, it ought to have some visibility.
We’ll treat all 0’s as missing values.
- Item_Weight has 1463
missing values (already explained above).
- Outlet_Size has a
unmatched factor levels.
These inference will help us in treating these
variable more accurately.
Graphical
Representation of Variables
I’m sure you would understand these variables
better when explained visually. Using graphs, we can analyze the data in 2
ways: Univariate Analysis and Bivariate Analysis.
Univariate analysis is done
with one variable. Bivariate analysis is done with two variables. Univariate
analysis is a lot easy to do. Hence, I’ll skip that part here. I’d recommend
you to try it at your end. Let’s now experiment doing bivariate analysis and
carve out hidden insights.
For visualization, I’ll use ggplot2 package.
These graphs would help us understand the distribution and frequency of
variables in the data set.
> ggplot(train, aes(x= Item_Visibility, y =
Item_Outlet_Sales)) + geom_point(size = 2.5, color="navy") +
xlab("Item Visibility") + ylab("Item Outlet Sales") +
ggtitle("Item Visibility vs Item Outlet Sales")

We can see that majority of
sales has been obtained from products having visibility less than 0.2. This
suggests that item_visibility < 2 must be an important factor in determining
sales. Let’s plot few more interesting graphs and explore such hidden stories.
> ggplot(train, aes(Outlet_Identifier,
Item_Outlet_Sales)) + geom_bar(stat = "identity", color =
"purple") +theme(axis.text.x = element_text(angle = 70, vjust = 0.5,
color = "black")) + ggtitle("Outlets vs Total Sales")
+ theme_bw()


Here, we infer that OUT027 has contributed to
majority of sales followed by OUT35. OUT10 and OUT19 have probably the least
footfall, thereby contributing to the least outlet sales.
> ggplot(train, aes(Item_Type,
Item_Outlet_Sales)) + geom_bar( stat = "identity") +theme(axis.text.x
= element_text(angle = 70, vjust = 0.5, color = "navy")) +
xlab("Item Type") + ylab("Item Outlet Sales")+ggtitle("Item
Type vs Sales")


From this graph, we can infer that Fruits and
Vegetables contribute to the highest amount of outlet sales followed by snack
foods and household products. This information can also be represented using a
box plot chart. The benefit of using a box plot is, you get to see the outlier
and mean deviation of corresponding levels of a variable (shown below).
> ggplot(train, aes(Item_Type, Item_MRP))
+geom_boxplot() +ggtitle("Box Plot") + theme(axis.text.x =
element_text(angle = 70, vjust = 0.5, color = "red")) +
xlab("Item Type") + ylab("Item MRP") + ggtitle("Item
Type vs Item MRP")


The black point you see, is an outlier. The mid
line you see in the box, is the mean value of each item type.
Now, we have an idea of the
variables and their importance on response variable. Let’s now move back to
where we started. Missing values. Now we’ll impute the missing values.
We saw variable Item_Weight
has missing values. Item_Weight is an continuous variable. Hence, in this case
we can impute missing values with mean / median of item_weight. These
are the most commonly used methods of imputing missing value.
In next post,will lsee how to combine the
data sets and analyze. This will save our time as we don’t need to write separate codes for
train and test data sets. To combine the two data frames, we must make sure
that they have equal columns, which is not the case.I deeply appreciate your kindness in reading my blog posts.and will meet in next post.
Thanks&Regards
NAGARJUNA MAHANTI
That is very interesting; you are a very skilled blogger. I have shared your website in my social networks! A very nice guide. I will definitely follow these tips. Thank you for sharing such detailed article.
ReplyDeleteR Programming Online Training|
Data Science Online Training|
Hadoop Online Training
Thank you so much for your kind words, valuable feedback and gracious support — all of which are very much appreciated.
ReplyDeleteIt is an awesome post.Keep posting.
ReplyDeleteJava training in Chennai
Java training in Bangalore
Java training in Hyderabad
Java Training in Coimbatore
Java Online Training
The rise of theIOT data analyticsover the last decade has brought with it a huge wealth of data that we can collect and analyze in order to better manage our businesses, as well as our lives. Data analytics is now a major selling point for many companies looking to build a competitive edge, and it's no surprise that the IoT is driving much of that growth.
ReplyDelete